Add numbers given in the form of Linked List
September 5, 2018Recursive Bubble Sort
October 14, 2018String Matching Algorithms
Given a string of characters, search for a pattern (another smaller string) in the string. For example, if given string is
Ritambhara Technologies for Coding Interviews
and the pattern is Tech, then the pattern is present in the string. If the pattern that we are looking for is Moksha, then this pattern is not present in the given string.
Naive search in a string
Write a function that accepts two strings, one representing the main string and other representing the pattern. Write code that searches for the pattern in the main string, and return true if it is present in the string and false otherwise.
There are many better algorithms like Robin Karp, KMP, etc. to solve this problem taking lesser time. Naive search is the brute force way of doing it. The idea here is to traverse the main string linearly, for each position, check if this position can be the starting point of the pattern inside the string.
int naiveSearch(char* str, char* pattern)
{
// n/m = no. of characters in str/pattern
int n = strlen(str); int m = strlen(pat);
for(int i=0; i <= n-m; i++){
int j;
// Check if pattern starts from index i
for(j=0; j<m; j++)
if (txt[i+j] != pat[j])
break;
if(j == m)
return 1; // PATTERN FOUND
}
return 0; // PATTERN NOT FOUND
}
The code above takes O(n*m) time to in the worst case.
Try answering this question: Given that all the characters in the pattern are unique. Change the logic in Code 1.11 so that it takes not more than O(n) time in the worst case.
Rabin-Karp
In naive string matching algorithm, we were comparing pattern with the (sub)string. Comparing strings of length m takes O(m) time. But hash values of two strings can be compared in constant time. Rabin Karp algorithm precomputes the hash values of the pattern and all the substrings of size m in the main string (m being the size of the pattern). For demonstration, let the string be
"a b c a a b b"
and the pattern is
"a b b"
The algorithm calculates the numeric hash value of the pattern. Then using the same hash function, it computes the hash of each string of length 3. For the sake of simplicity, let us use the below method to calculate the hash of a string
Calculating Hash 1. Associate a numeric value with each character. This value can be the ASCII value, but for simplicity sake let us associate the following values
a = 1, b=2, c=3,d=4, …, z = 26
2. add the number value of all characters.
sum = Sum of (numeric values of characters)
3. Take the MOD of the sum with 13 (in practice a much larger prime number is used).
Hash = sum % 13
Using the above method, the hash value of the given pattern is 5
(1+2+2)%13 = 5
Next, we compute the hash of all the substrings of string abcaabb of size 3 and store them in a numeric array as shown below.
Size of numeric hash array is 5(n-m) because there are 5 substrings of size 3 (abc, bca, caa, aab, abb). Hash of each substring is shown in Figure.
The above hash values are computed in linear time using the rolling hash technique. A rolling hash use hash value of the previous substring to compute the hash of next substring in constant time without rehashing the entire substring. These hash values are computed as below:
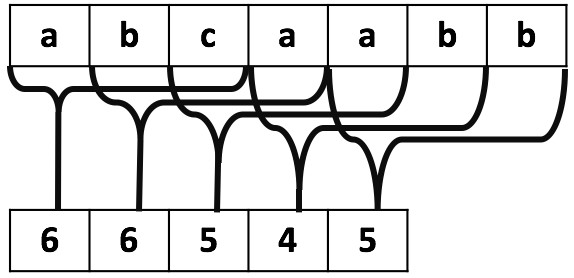
Compute the hash of abc
Hash(bca) = (Hash(abc) – NumericValue(str[0]) + NumericValue(atr[3]))%13
= 6
For each successive substring, we remove the numeric value of outgoing character and add the numeric value of the incoming character to compute the hash of new substring.
The Hash of our pattern was 5 and hash of first substring (abc) is 6. We can conclude, without actual comparison that pattern does not match with the first three characters of the string. Similarly, we can conclude that pattern is not equal to the next three characters whose hash is also 6.
Rather than searching for the pattern in string, we look for 5 in the hash array. Each value of hash array corresponds to a substring of length 3 in the String. 5 is present at two places, corresponding to substrings caa and abb. It is not guaranteed that these substrings are equal to the pattern, but it is guaranteed that pattern is not equal to any other substring. If two strings are equal then their hash values are also equal, but vice-versa is not true.
The pattern is compared with these two substrings and one of them is found to be equal to the pattern.
The hash method suggested in Rabin-Karp is more complex to minimize the spurious hits. We have used a much simpler version to demonstrate the idea.
Ideally, each character’s numeric value should be multiplied with some power of a larger prime number, to avoid the match with a different permutation of pattern characters.
In the worst case, Rabin Karp may take the same time as the naive algorithm, but average time taken is O(n+m).
(The video is in Hindi-English mix)
KMP Algorithm
The video below explains the KMP algorithm in detail (The video is in Hindi-English mix)