Birthday Paradox (Birthday Problem)
August 4, 2017HashMap performance improvement in Java 8
August 5, 2017Separate Chaining: Hashing collision handling technique
It is almost impossible to design a generic hash system without collision. In case of collision, it need to be handled. There are multiple ways of handling collision. Separate chaining is one of such techniques.
For an introduction to Hashing, see this post.
When hash function return the same result for more than one values, it is called Collision. If hash function is
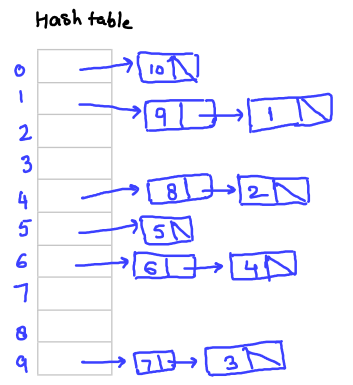
H(x) = x2 MOD 10
And numbers are {1, 2, 3, 4, 5, 6, 7, 8, 9, 10} then, they gets populated in the hash table as below:

To see how likely it is to have collision, have a look at the Birtday paradox, with only 23 persons, the probability that two people have same birthday is 50%.
The idea of separate chaining is to create a linked list of elements at collision. For each entry in the hash table is a pointer to the linked list of values stored at the entry.
Insertion an element in the hash table is a two step process,
- Compute the hash key using Hash function.
- Insert at the head of linked list at that key.
Searching in the hash is also a two step process:
- Compute the hash key using Hash function.
- Search in the linked list at that key.
The worst case happens when all the values hash to the same key. This will make the search operation take O(n) time. But this is a near impossibility in any good hash implementation.
If collisions are very less, then search takes constant time.
There are many advantages of separate chaining to resolve collision:
1) It is simple to implement.
2) It is dynamic and can be extended at run times. Use it if you do not know how many and how frequently keys may be inserted or deleted.
It comes with a cost of space. Needs more space for pointers and in the worst case may end up taking more memory. Java was using this technique till jdk 1.7 in HashMap implementation. After that they made minor change and got about 20% boost in their performance. Will discuss it in next post.